是否深陷原码反码补码的漩涡无法自拔,掌握overflow的概念就可以挣脱
up主 饭神来了 408补习班第八期
int 在计算机中是有限的整数序列
既然是有限的,那就必然有溢出(Overflow)
溢出因为bit的位数是固定的
引入负数/有符号数的二进制表示后:
存在两个问题:
- 0有+0和-0两种表示
- 负数的加减法doesn't work
eg. 001(1)+101 (-1)= 110(-2)
To make it work:
引入另外一种表示法
让001+(-1)=000
那这个-1应该用什么表示呢,没错就是111
001 + 111 = 1 000(发生了溢出)
找到了-1的表示,那-2怎么表示呢? - -1 -1 =-2
- 111 -001 = 110
可以看到it still works
验证一下: - -2 +2 =0
- 110 + 010 = 1 000(overfow)对了
- -2 + 5 =3
- 110 + 101 = 1 011(overflow)对了
下面用简单的方式找到-x的表示方法:
Flipping each bit and adding 1:
-x = ~x+1
5 - 0101 This is 5
- 1010 This is the "Ones complement of 5" 5 with bit filpped
- 1011 This is the "Twos complement of 5" 5 with bit filpped and added 1
比如前面的-1 - 01 flip 10
- add 1 ->11
- 加上符号111
把111称为1的Twos complemnt of 1
"Ones complement of x"在中文教材里被翻译为反码
"Twos complement of x"在中文教材里被翻译为补码
对于相关翻译deepseek的理解
They are called complements because complementary bits are set.If they are added, all bits are necessarily set:
把比特位填满
0101 +1010 =1111
Adding 1 to the sum of a number and its complement necessarily results in a 0 due to overflow
通过+1溢出得到0
(0101 + 1010 ) + 1 = 1111 +1 = 1 0000 (0)
这完美利用了溢出的方式实现了对一个数负数的表示
And if x+y=0,y must equal -x
补码的引入是为了解决负数的计算,利用了溢出(overflow)的概念使得正数+负数=0
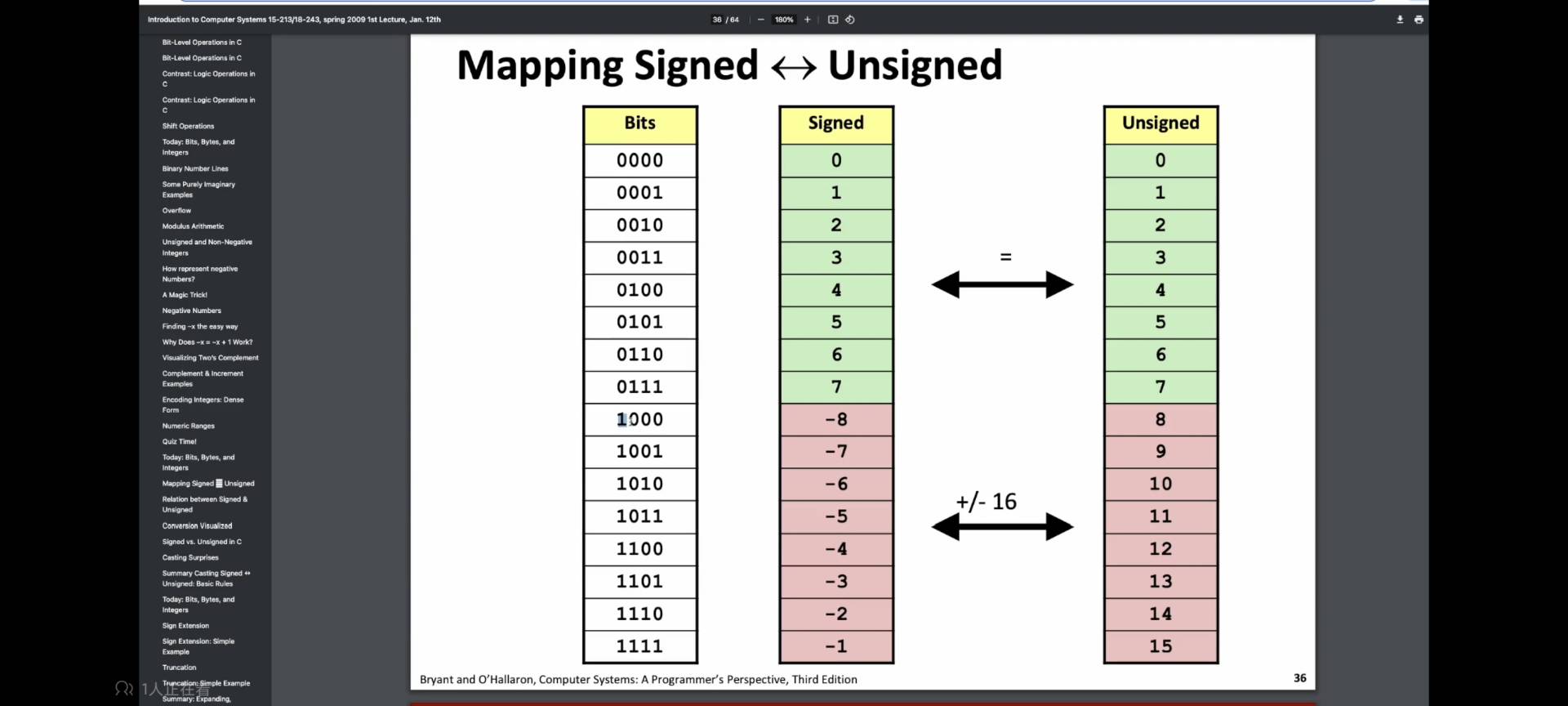
有符号数以及无符号数对于二进制数的映射
拆解:
对于有符号数可以看成一个最大的负数加上一个正数,
如1010
- 1000 (-8)
- 0010 (2)
- 1000 + 0010 = 1010 (-8 +2 =-6)
同理对于无符号数拆成一个最大的正数加上一个正数: - 1000 (8)
- 0010 (2)
- 1000 + 0010 =1010 (8+2=10)
第三章 存储系统
层次结构
主存-辅存之间交换 由硬件和操作系统完成 系统程序员需要完成操作系统的页面置换算法
- 实现虚拟存储系统,解决主存容量不够的问题
cache-主存之间交换由硬件工程师实现 对于系统程序员是透明的 - 解决了CPU 主存之间速度不匹配的问题
分类
- 按照层次分类
- 按存储介质分类
- 按存取方式分类
- 按信息的可更改性
- 按信息的可保存性
- DRAM和SRAM RAM相关
性能指标
- 存储容量
- 单位成本(每bit价格)
- 数据传输率(主存带宽)
- 存储周期=存取时间+恢复时间
存储器芯片基本结构
- 存储体
- MAR
- MDR
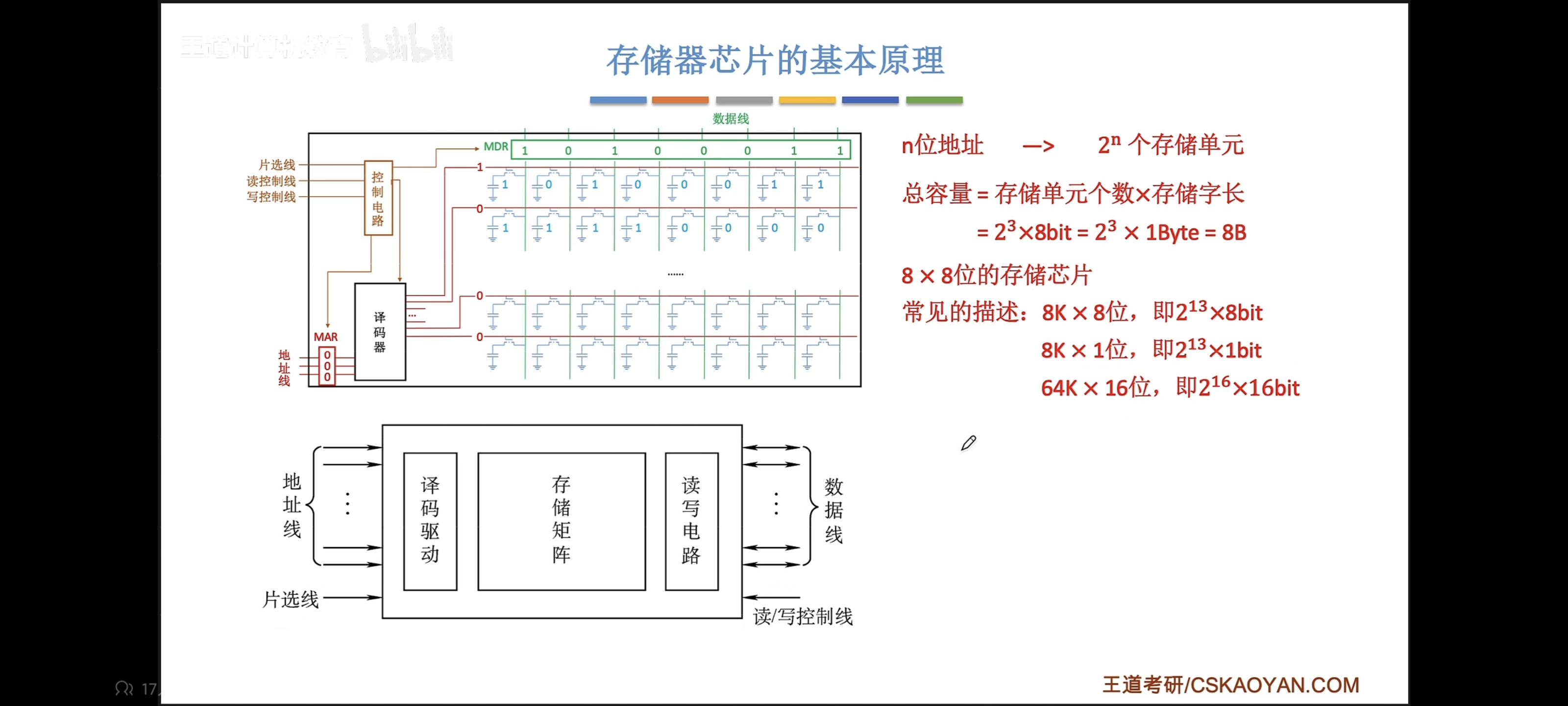
字位线的理解参考这个视频:【用最好的动画为你讲解--内存的原理-哔哩哔哩】 https://b23.tv/QW3yoVf
SRAM和DRAM
- DRAM Dynamic Random Access Memory 动态RAM
- SRAM Static Random Access Memory 静态RAM
- SDRAM Synchonous Dynamic Random Access Memory 动态RAM
都属于断电易失
DRAM用于主存(现过时,通常采用SDRAM)
- 使用栅极电容存储信息,破坏性读出,需要重写,速度更慢
- 每个存储源电路简单,制造成本更低,集成度高,功耗低
- 需要刷新
- 分两次送行列地址(地址线复用技术->地址线、地址引脚减半)
SRAM用于cache - 使用双稳态触发器存储信息,非破坏性读出,无需重写,速度更快
- 每个存储元电路较栅极电容更复杂,集成度成本更高,集成度低,功耗大
- 无需刷新
- 同时送行列地址(集成度低)
DRAM的刷新
多久刷新一次:刷新周期,通常是2ms
每次刷新多少存储单元:一行
使用行列地址:减少选通线的数量 16x16 ->16+16
如何刷新:有硬件支持,读出一行信息,然后把这个信息重新写入,占一个读写周期
在什么时候刷新: - 分散刷新
- 集中刷新
- 异步刷新
ROM
- MROM Mask Read-Only Memory 掩模式只读存储器 芯片生产时写入,任何人不可重写
- PROM Programmable 可用专用的PROM写入器写入写一次后就不能读写
- EPROM Erasable Programmable 可进行多次重写
- UVEPROM Ultraviolet rays 紫外线照射擦除,只能擦除全部
- EEPROM(
PROM) 采用电擦除,擦除特定的字 - Flash Memory (eg.U盘,sd卡) 断电后也能保存信息,由于写入要擦除,因此写比读慢
- SSD Solid State Disk 由控制单元和存储单元(Flash芯片)组成,控制单元和闪存不一样
实际上主板上保存BIOS的ROM芯片也是主存的一部分,与RAM二者统一编址
详细内存布局表
| 地址范围 | 类型 | 用途 |
|---|---|---|
0x0000~0x03FF |
ROM | BIOS/固件存储 |
0x0400~0x7FFF |
RAM | 程序运行和数据存储 |
0x8000~0x8FFF |
VRAM | 显存 |
0x9000~0xFFFF |
I/O | 外设 I/O 映射 |
- 很多ROM也能进行写入
- 很多ROM也具有随机存取的特性
- 闪存写入更慢因为要擦除
多模块存储器
读取周期
T = r + 3r
读取时间(总线传输周期)r 恢复时间3r 读取时间r 恢复时间3r
多体并行存储器
- 高位交叉编址
| 体号 | 体内地址 |
|---|---|
| 00 | 000 |
- 低位交叉编址
| 体内地址 | 体号 |
|---|---|
| 000 | 00 |
| 适合连续访问存储 |
单体多字存储器
只能CP一次读一整行,会有冗余信息
主存储器和CPU的连接
- 单块存储器与CPU的连接
数据总线宽度=主存存储字长,才能尽可能发挥数据总线的性能
单块存储芯片的数据字长<数据总线宽度
位扩展 一个8K x 1位的存储芯片,代表这个芯片有8K个存储单元 每个存储单元存储1bit
假设数据总线宽度为8位,
字扩展 一个8K x 8位的存储芯片,位数已经和总线的位数相同了,这时数据总线的性能以及最高了,不需要拓展位,要拓展存储器的存储字数
假设CPU的地址总线有16位
这时如果是有两个存储芯片进行字扩展,指定
改进一下,把一根多余的A,连接到两个片选信号上,但其中一个加上非门(1,2)译码器,这时一位A就能链接两个存储芯片,再拓宽思路3根线可以表示
以这个原理译码器命名规则应该是
结合一下还有字位同时扩展法
译码器 除了
磁盘存储器
外存储器 又称辅助存储器 Secondary Memory
主要使用磁表面存储器 如磁盘 磁带 磁鼓
优点:
- 存储容量大,位价格低
- 记录介质可以重复使用
- 记录信息可以长期保存不丢失
- 非破坏性读出
缺点: - 存储速度慢
- 机械结构复杂
- 易受环境影响(强磁场)
磁盘设备的组成 - 磁头(多个)
- 盘面(多个)
- 磁道
- 柱面 (相同位置的磁道组成)
- 扇区 (一个磁道被划分成多个扇形区域)每个扇区的大小相等,内侧的磁道的半径小,扇区长度短,位密度更高,外侧的位密度小,保证了扇区大小相同,也可以得出每个磁道能存储的大小相同
性能指标:
- 磁盘容量
- 非格式化容量
- 格式化容量
- 记录密度
- 道密度 沿着半径方向单位长度磁道数
- 位密度 磁道单位长度能记录的二进制代码数
- 面密度 位密度
道密度
- 平均存取时间
- 寻道时间(磁头移动到磁道)
- 旋转延迟时间(磁头定位到所在扇区)题目没给就是转半圈所用的时间
- 传输时间 (传输数据所花费的时间)
- 磁盘控制器延迟(可能)
平均存取时间是以上的总和
- 数据传输率
单位时间内向主机传送数据的字节数,假设转速为r(转/s),每条磁道容量为N个字节,则数据传输率为
磁盘地址:
| 驱动器号 | 柱面号 | 盘面号 | 扇区号 |
|---|
工作过程:
- 寻址
- 读盘
- 写盘
- 每个操作对应一个控制字,硬盘工作时,第一步是读取控制字,第二步是执行控制字
- 磁盘属于机械式部件,读写操作是串行的,不可能同时读写操作,也不能同时对多个数据读写
磁盘阵列
RAID(Redundant Array of Inexpensive Disks) 将多个独立的物理磁盘组成一个独立的逻辑盘,数据在多个物理盘上分割交叉存储、并行访问,有更好的存储性能、可靠性、安全性 - RAID0 无容错能量
- RAID1 有容错能力,容量减少一半
- RAID2
- RAID3
- RAID4
- RAID5
越往后可靠性越高,利用磁盘阵列提高磁盘的可靠性
固态硬盘SSD
原理:基于Flash memory ,属于电可擦除ROM,即EEPROM
组成:
- 闪存翻译层 负责翻译逻辑块号,找到对应页
- 存储介质 多个闪存芯片(Flash chip)
闪存芯片组成- 块(block) 一个闪存芯片被分为多个块 相当于磁盘里的磁道
- 页(page) 每个块被分为多个页 相当于磁盘里的扇区
读写特性:
- 以页为单位读写
- 以块为单位擦除,擦除的每个页都可以写一次,读无限次、
- 支持随机访问,给一个逻辑地址,闪存翻译层可以通过电路迅速定位到对应的物理地址
- 读快,写慢,因为如果要写的页上有数据(应该是要进行覆盖操作),会把当前块的其它页都复制到一个新的(擦除过的)块,在新的块上写入那个页的数据,然后把原来的块擦除,闪存翻译层再把逻辑块号映射到数据被复制到的那个块上
与机械硬盘对比: - 读写速度快,随机访问性能高,因为机械硬盘需要移动磁头磁臂
- 安静无噪音,抗摔,能耗低,造价更贵
- 重复(擦除)写一个块次数过多可能会坏掉,机械硬盘不会
磨损均衡技术: - 思想:将擦除平均分布在各个块上,提高使用寿命
- 动态磨损均衡技术 写入数据时,优先选择擦除次数最少的新内存块
- 静态磨损均衡技术 监测进行数据分配迁移,让老内存卡承担读多写少(减少擦除次数)的任务,让新的内存块承担更多的写任务
Cache基本原理 基本概念
局部性原理
- 空间局部性 最近的未来要用到的信息(指令和数据)。很可能与现在正在使用的信息在存储空间上是连续的
- 时间局部性 最近的未来要用到的信息,可能是现在正在使用的信息
如果程序按列优先访问二维数组,空间局部性会更差
性能分析
命中:如果cpu想要访问的数据能直接在Cache中找到
命中率H:CPU要访问的信息在Cache中的比率
缺失(未命中)率M:=1-H
设
Cache-主存系统的平均访问时间t
(先访问Cache,访问不到再访问主存)
前面是Cache命中的时间,后面的是Cache找不到加上去主存里找的时间(主存和Cache同时访问)
根据局部性原理,可以把CPU目前访问的地址周围的部分数据放到Cache中,如何界定周围的实现?
把主存的存储空间分块,主存与Cache直接以块为单位进行数据交换
主存的分块也被称为一个页 页面 页框
Cache的块也被称做行
这里的术语容易混淆,需要结合deepseek理解术语区分
待解决问题:
- 如何区分Cache与主存对应关系? -> [[#Cache和主存的映射方式]]
- Cache很小,主存很大,Cache满了怎么办? ->[[#替换算法]]
- CPU修改了Cache中的数据副本,如何保证主存中的数据母本与副本的一致性 ->[[#Cache写策略]]
Cache 和主存映射关系
- 全相连映射 主存块可以放在Cache任意位置
- 直接映射 主存块只能放到一个特定的位置
- 组相连映射 Cache分为若干组,每个主存块可以放到特定分组中的任何一个位置
全相连映射
- Cache存储空间利用很充分,Cache命中率高
- 查找标记很慢
直接映射
组相连映射
Cache替换算法
Cache被装满后应该怎么办
全相连映射 Cache全部满了才需要替换 需在全局内选择替换哪一块
直接映射 对应位置非空,直接替换
组相连映射 对应分组满了才替换 需要在分组内选择替换哪一块
随机算法
若Cache已满,随机选择一块进行替换
没有考虑到程序的局部性原理 命中率低,实际效果不稳定
先进先出算法FIFO
若Cache已满,则替换最先被调入Cache的块
仍然没考虑局部性原理,最先被调入的块也可能被频繁访问
抖动现象:频繁地换入换出的现象(刚被替换掉又被调入)
近期最少使用算法LRU
为每一个Cache块设置一个计数器,用于记录Cache块有多久没被访问了,Cache满后替换计数器最大的
手算快速方法,假设有四个Cache块,Cache未命中,看它前面出现的那三个不同的是什么,因为刚被使用,保留,剩下那一个被替换
- ..
- ..
- ..
比它小的加一是因为比它大的加一没有意义
四个Cache块只需要2个bit位计数
考虑了局部性原理,近期被使用的,在不久的将来也很有可能被再次访问,淘汰最久没访问过的
Cache命中率高,若频繁访问的主存块数>Cache块数,也有可能发生抖动
最不经常使用算法LFU least frequently used
为每一个Cache块设置一个计数器,记录每个Cache块被访问了多少次,Cache满时替换计数器最小的
- 算法:
需要很多个计数器
曾经经常被访问的主存块在未来不一定会被用到,如视频聊天的块,实际运行效率不如LRU